Introduction
Stream processing saves programs from having to load data
entirely into memory.
Instead, a program gets a hold on a stream instead of the
actual data. The program then starts asking the stream to send a chunk of the
data. The program does the required processing on this chunk, and then asks for
another chunk…this goes on until the entire stream is read and processed.
This has the very important advantage of not having to
load the entire message at once into the program’s memory space. By reading
data in chunk, only the size of the chunk that is being processes is loaded
into memory.
In systems under load and where scalability is a concern,
this can have a huge influence on the success these systems.
This post, explains how stream processing is
implemented in BizTalk Server, and how to take advantage of streaming to build
better BizTalk applications.
Stream Processing Support in BizTalk
BizTalk implements a forward-only streaming design.
Forward-only means that the stream can only be read, and cannot be seeked back.
Stream processing is used across BizTalk:
--Out of the box pipelines are stream-based; they utilize
streaming when fetching data from the adapter and as data passes from one stage
to another. For example, out-of-the box components such as the Flat-File
Disassembler and the XML Disassembler, are built with streaming in mind.
When writing custom pipeline components, although
harder to implement, you should use the streaming approach instead of loading
the entire data into memory; especially for systems that will be under heavy
load. This module takes an in-depth look at pipeline stream programming.
--Orchestrations also support streaming. When calling
.NET components from within an OX, streaming can also be used to improve Ox
performance. Since this discussion requires the understanding of Ox engine, I
will discuss streaming support in orchestrations in the business process
module.
--Mapping also supports streaming. By default, XSLT
typically requires loading messages into memory to perform transformation;
which obviously contradicts with BizTalk streaming model. As such, BizTalk
implements virtual streaming for mappers. If a message size is over 1MB,
BizTalk virtual streaming writes the data into a temporary file, and this file
is now used as the stream source instead of memory. This introduces I/O
overhead, but still much better than any potential memory issues. This might
not be very clear yet, but I will discuss Virtual Streaming later.
--BAM introduces significant overhead over BizTalk
because its constantly saving data into the BAM database. To reduce this
overhead, BAM contains a set of event streams.
Streaming in Pipelines
When used in pipeline components, stream processing
solves two major issues:
--First, as I said before, it reduces memory consumption
by not loading the entire data into memory
--A second advantage, is that it speeds up processing, because the next component does not have to wait for the current component to
finish processing the entire message.
Instead, the current component passes to the next
component the portion of the stream it has finished processing, and starts
working on the next portion.
The No-Streaming Approach
To best appreciate the value of streaming, lets assume
that you have a built a custom pipeline, and in its various stages, you have
created custom pipeline components without adopting the streaming approach.
--An adapter which is listening for data on the wire,
creates a new BizTalk message of type IBaseMessage and if there are any message
parts, also creates parts of type IBasePart. It then attaches the data stream
to this message and promotes context properties related to the receive
endpoint. The adapter then submits the message to the pipeline.
Now before going on, make sure you understood this. Note,
that the adapter has not actually read the data from the wire. It just created
a message type that BizTalk can understand, and it only attached the data
stream to that message, but no data has been read yet.
--Now the first component of the first stage in the
pipeline gets the message. At this moment, the component reads the entire data
stream attached to the memory at once. This effectively loads the entire
message into memory. The component will do whatever processing required, then
it creates another stream componsed of the new data and passes it along to the
other component in the pipeline chain.
--Now this other component, again reads the entire data
stream at once, causing the entire to message to be loaded into memory again,
does the required processing, creates a new stream, and passes it along to the
next component
this process continues until all components of the
pipeline are executed and the final message is submitted by the Message Agent
to the MessageBox.
Now this should give you an idea about how bad such
design will perform, especially for big size messages and systems with high
load. This alone, can cause your system to break.
Actually, this is the most used approach by pipeline
developers since it’s the easiest.
What is also bad, is that although out-of-the box
pipeline components such as the XMLDisassembler or XmlValidator implement
streaming; if you create a custom pipeline and mix these components with your
own custom components that are not utilizing streaming; then this breaks up
the streaming chain, and again loads the entire message into memory.
The Streaming Approach
Now lets see how streaming would change how data is
processed, and how this affects the overall performance.
--The adapter, attaches the data stream to the
IBaseMessage, and passes it to the pipeline.
--The first component receives the message. Now, again
remember that the message has the data stream attached to it, but the data has
not actually been read yet. This component then wraps the message with a
custom stream; without reading any part of it. Now the message with the new
stream attached, is passed on to the next component.
--The next component does the same: it wraps yet another
new stream around the one passed to it, and again passes on the message to the
next stage.
Now the message has a chain of two streams attached to
it…and still no data has been read yet.
The message goes through the same process, while going
through all pipeline components.
--Finally, it’s the EPM that calls the stream’s Read()
method. At this moment, the call gets propagated through all those custom
streams that have been wrapped around the message by the pipeline component,
all the way to the main data stream of the adapter.
--The adapter then performs the first actual data read
and passes it along the stream to the first component.
--Each pipeline component then executes its own
implementation of the Read() method on that specific stream chunk it receives.
--After passing through all components, this stream chunk
is then handed to the EPM which hands it over to the Message Agent.
This continues until the stream is read entirely and
the message is stored in the MessageBox.
Once the message is stored entirely in the MessageBox,
the EPM notifies the adapter so that it performs resources cleanup; for
example, a File adapter deletes the file and a
SQL Adapter disposes the connection.
On the send side, the Message Agent hands the adapter, a
reference to the message. The adapter then starts pulling the stream from the
messagebox and through the send pipeline. Data is then sent to the wire is a
streaming fashion.
So why do you care about understanding streams? Well
beyond the fact that’s cool to understand things, this affects how you design
your pipeline components.
Streaming Sample
To test the performance difference when using the streaming vs. non-streaming approach, I created
a pipeline component which uses the memory approach (non-streaming). nothing special about its Execute method, it just acts as a passthrough component:

Next I created, a custom pipeline component that uses streaming.
First. I created a custom stream class which derives from
System.IO.Stream:
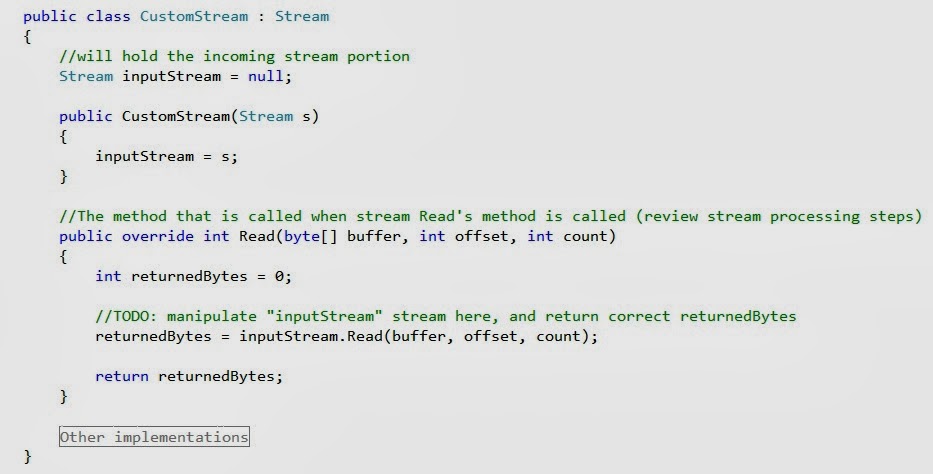
The reason for this, is that I need to provide my own
implementation of the Read method.
Recall from when I explained stream processing, that the
Read method gets called by the EPM to trigger the start of stream processing.
Its within this Read method that you provide the logic
that you want to perform; however, recall that here you are processing just a
chunk of the stream and not the entire message.
Now again, for this demo, I am just passing the data
along with no processing…so here I am simply returning the same set of bytes
unchanged.
In this case, in the Execute method of the Icomponent
interface, and unlike the previous component, where the entire message is
loaded memory;
here I just wrap the incoming body stream with my custom
stream implementation and then replace the stream with the result of my custom
implementation:

Remember that at the first pass of pipeline components,
the execute method just creates a new wrapper stream.
When all components do so, finally the Read method, is
executed where each stream is processed and data is updated.
To run the sample, in my BizTalk application, I have a receive location
which is configured to use the pipeline using the in-memory approach.
In my file system, I have created a large message, which
is around 120 Meg.
Before dropping this file into the in folder, I examined how much memory is the Biztalk host instance process consuming; it was nearly 18K:

When I dropped the file, I examineD the memory
consumed while the host instance is pulling the file. I could see the memory increasing until nearly hitting 300 K…so going from 18k to 300k for consuming a
single file of 120 Megs:

I then changed the pipeline used in my receive
location to the one utilizing streaming.
After dropping the file again and checking the host
instance processes…I could see its rising to nearly 54 K…so there is a difference of around
250 K of memory between the first and second approach:

Now imagine, what this means for a project that is
receiving thousands of messages who in real world can be much larger than 120
Meg...
Out of the Box Streams
Besides writing your own stream implementations, BizTalk
provides out of the box stream implementations in the the
Microsoft.BizTalk.Streaming assembly:
--EventingReadStream is an abstract stream class, which
allows you to hook up event handlers to certain events, such as the first and
last stream chunk reads. Classes such as ForwardOnlyEventingReadStream extend
this class, as shown by this example.
--VirtualStream is probably the most used out-of-the box
stream because its simple to use. Here, data is still held in memory – as if
you are using the in-memory approach – however, this happens only until data
size exceeds a configured value; at which stage it is written into a disk file.
And from this moment, the disk file becomes the stream source.
You can think of VirtualStream as being somewhat
similar to the MemoryStream, however it uses a disk file for data storage
instead of memory.
So, the VirtualStream solves the problem of loading
large data into memory – in the expense of I/O overhead. Despite this I/O
overhead, still its much better than any memory problems.
If implementing custom streams – for whatever reason – is
not an option, or at least a very difficult option to implement, then this
stream is your safest bet.
--The ReadOnlySeekableStream provides seekable read-only
access to a stream.
This example, shows how to use VirtualStream and
ReadOnlySeekableStream together, to wrap the original stream:
This will result in the VirtualStream saving data into a
temporary file system. And the ReadOnlySeekableStream, providing seekable
readonly access to the stream
You can see all stream implementations inside the
Microsoft.BizTalk.Streaming assembly using the following URL:
Best Practices Accessing Stream Data
We already discussed how streams is a much better option
to use in pipeline components as opposed to using XmlDocument which loads the
entire message into memory.
So since we cannot use the known methods of XmlDocument
such SelectNodes and SelectSingleNode, what options do we have natively from
BizTalk Server that will help us navigate the message?
Microsoft.BizTalk.XPathReader assembly provides the
XPathReader and XPathCollection classes.
Below is an example, that shows how these classes can
be used to navigate the stream after it has been wrapped by the VirtualStream
and ReadOnlySeekableStream:

Of course you can use classes such as XPathReader and
XPathCollection, on any stream; including custom streams such as the one I have
showed you before.
Streaming Support in Orchestrations
The other place, where streaming plays an important role
and affects the way you design your code, is inside Oxs.
However, since this requires the knowledge of Ox XLANG
engine, streaming in Oxs will be discussed in a future post.
No comments:
Post a Comment